
Learning to summarize from human feedback
Jul 23, 2023
»
nlp
Learning to Summurize from Human Feedback
ChatGPT has significantly influenced the AI industry. Its origins can be traced back to the paper, Training Language Models to Follow Instructions with Human Feedback which follows the methodology detailed in Learning to Summarize from Human Feedback. So, before examining Instruct GPT, I would like to first dig into the paper of the title where it well utilized the Reinforcement Learning from Human Feedback (RLHF).
Abstract
- Summarization models has not well evaluated its performance due to bottleneck of the data and metrics. (Traditional ROUGE, which does not regard human preference)
- Researchers collected large amount of high quality summarization dataset, trained a reward model to predict human preference of the summary and fine tuned the large language model with reinforcement learning
- It worked well on many dataset.
- Especially, trained reward model well generalizes new datasets.
Introduction
- LLM achieved high performance, but its generalization mostly relied on supervised fine tuning, where it is fragile to misalignment between fine-tuning objective and human preference.
- Token predicting maximum likelihood objectives does not regard hallucinations or harmful response, also, low quality data is weighted same as important ones. (Very fragile to distribution shift, too)
- Methodology follows the Fine-tuning language models from human preferences which fine tuned language model from human feedback using reward model.
- Then, train a policy via RL to maximize the reward from the trained reward model. Policy generates a token and is updated using PPO algorithm.
-
Used 6.7B GPT-3 model
Main contribution
- Showed RLHF’s powerful performance.
- Showed human feedback models’ string generalization ability.
- Conducted empirical study on policy and reward model
- Publicly released human feedback dataset.
Related work
Fine-tuning language models from human preferences
- In common
- Transformer
- Optimized human feedback across a range of tasks.
- Same dataset (Reddit TL;DR and CNN/DM)
- Difference
- Online manner
- Highly extractive
- Disagreement with labelers and researchers
- Smaller model.
Method and experimental details
High-level methodology
- Collect samples from existing policies and send comparisons to humans
- Various summaries including result from initial policy, current policy, original reference, other baseline
- Rank them with labelers, choosing best one
- Train reward model from human comparisons.
- Reward model predict log odds of which summary is better.
- Optimize using PPO with the reward model.
- Trained reward model as a reward function
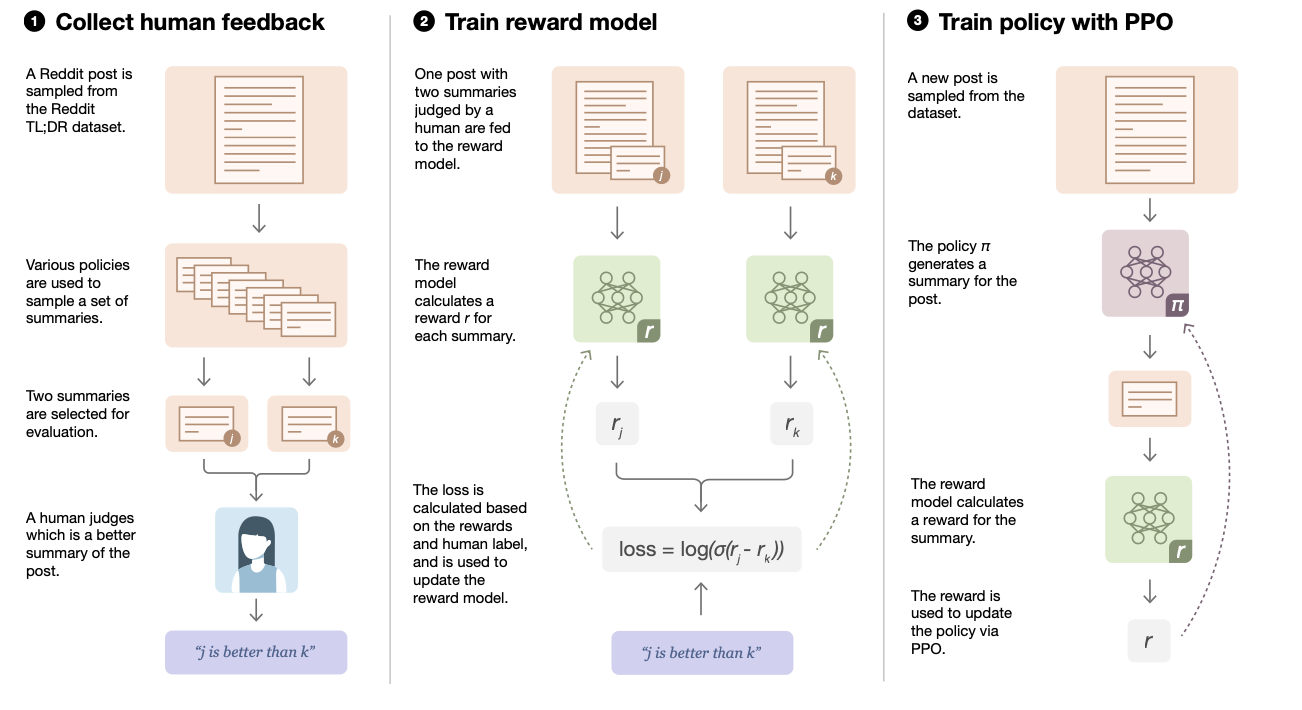
- Iterate above process, collecting more data at the same time.
Datasets and tasks
Datasets
- Datasets
- TL;DR summarization dataset, ~3M postings from reddit.
- Filtered, leaving 120,000 posts in result.
- GT task
- produce under 48 tokens long summary
- Collection of HF
- Previous work reported mismatch between labelers and researchers.
- Managed labelers better than previous works, resulted in better match.
Model
- Pretrained models
- GPT-3, 1.3B, 6.7B
- Supervised baselines
- Fine tune model in supervised manner.
- Usage (1) sample initial summary for comparison (2) initialize policy and reward models (3) baseline for evaluation
- low temperature (degree of diversity), no nucleus sampling (comulative top p sampling with threshold)
- supervised fine tuned model itself was already SOTA on ROUGE
-
Reward model
- Starting from supervised baseline, append a linear head that outputs a scalar value, which is trained to represent human preference on summary.
-
given a post $x$, predict $y \in {y_0,\ y_1}$, if $y_i$ is a preferred one, Reward model loss is as
\[\text{loss}(r_\theta) = -\mathbb{E}_(x,y_0,y_1,i) \sim D[\log(\sigma\left(r_\theta(x, y_i)-r_\theta(x, y_{1-i})))\right]\] - $r_\theta(x, y)$ is scalar output of the RM, $D$ is the dataset of human judgements
- At the end of the training, normalize the reward model to output reference summaries from our dataset achieve a mean score of 0.
- Human feedback policies
- Trained reward model $\rightarrow$ policy generating higher quality outputs as judged by humans
- Output of reward model as a reward to maximize with the PPO algorithm. (Time step : BPE token)
- **Included penalty of KL divergence between updated RL policy $\pi_\phi^{RL}$ with the original supervised model $\pi^{SFT}$ $\rightarrow$ PPO!
- Act as entropy bonus, encouraging policy to explore and prevent it from collapsing a single mode
- Ensure the policy only learn output that is similar from the data reward model saw during training
- The logarithm of this ratio, multiplied by $\beta$, forms a penalty term that discourages the RL model from generating summaries that are too different from what the initial SFT model would generate.
- PPO value functions
- transformer with separate parameters from the policy $\rightarrow$ prevent updates from destroying pretrained policy.
- To get better understanding of the value function used, I attach link to a post that well explain the role and meaning of the value function
- Link
- The PPO-Clip algorithm can follow an Actor-Critic based training paradigm. The Critic is responsible for giving us the Q-values $Q(s, a)$ also referred to as a Value function. The value function is represented by another Transformer model initialized with the same weights as the reward model. Since the authors don’t mention any other information regarding the Value function, we assume that they optimize it by minimizing the difference between the Value function’s predicted reward and the actual reward provided by the Reward function.
Results
Summarizing Reddit posts from human feedback
- Policies trained with human feedback are preferred to much larger supervised policies
- Metric : percentage of summaries generated by the policy but preferred by human than the reference
- 1.3B RLHF Model 61% VS. 6.7B SFT Model 43%
- Controlling for summary length
- After forcing the model to output shorter one, preference rate slightly dropped by 6%, but still better than baselines.
- To control the length, researchers added a log length ratio term to regularize longer summary.
- Why policy improves result? - Four assessment - Coverage (important ones included or not) - Accuracy (to what degree the statements in the summary are stated in the post) - Coherence (easiness of summary to read) - Overall quality - RLHF model outperform the all other baselines. - 7/7 scores 45% of the time. - Especially well done with coverage.
Transfer to summarizing news articles
- Without further training, model well generated summaries of news articles.
- Perform almost as well as 6.7B fine tuned on news data.
Understanding the reward model
What happens as we optimize the reward model?
- Purpose of the reward model is to align policy with human preference, but the model is not a perfect representation of the human preference, since it had limited capacity and small data.
- Researchers prepared wide range of policies varying in KL penalty coefficient.
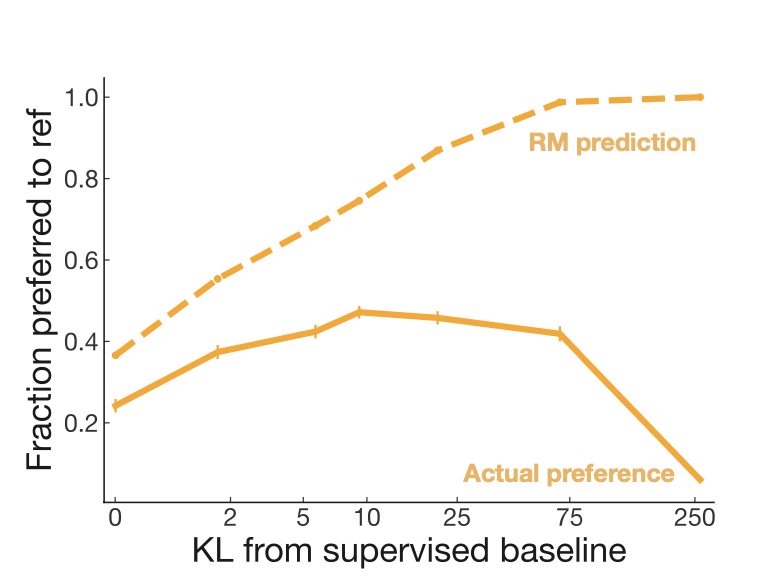
- Without KL penalization model overfitted, resulting in output that is against the actual preference. Which means, PPO is appropriate, forcing the policy partly stay to the pretrained, fine-tuned policy.
How does reward modeling scale with increasing model and data size?
- Larger model showed better result.
- Double the data increased average 1.1% of the reward model validation set accuracy, but Doubling the model size led to average 1.8% increase.
What has the reward model learned?
- TL;DR trained reward model well generalized the CNN/DM, the news dataset.
- Reward models are sensitive to small but semantically important details in the summary.
- Reward model slightly prefer longer ones.
Analyzing automatic metrics for summarization
- Evaluation
- Trained reward model outperformed other metrics, for example, ROUGE, in terms of agreement with the labelers (ROUGE ~57% agreement among labelers).